
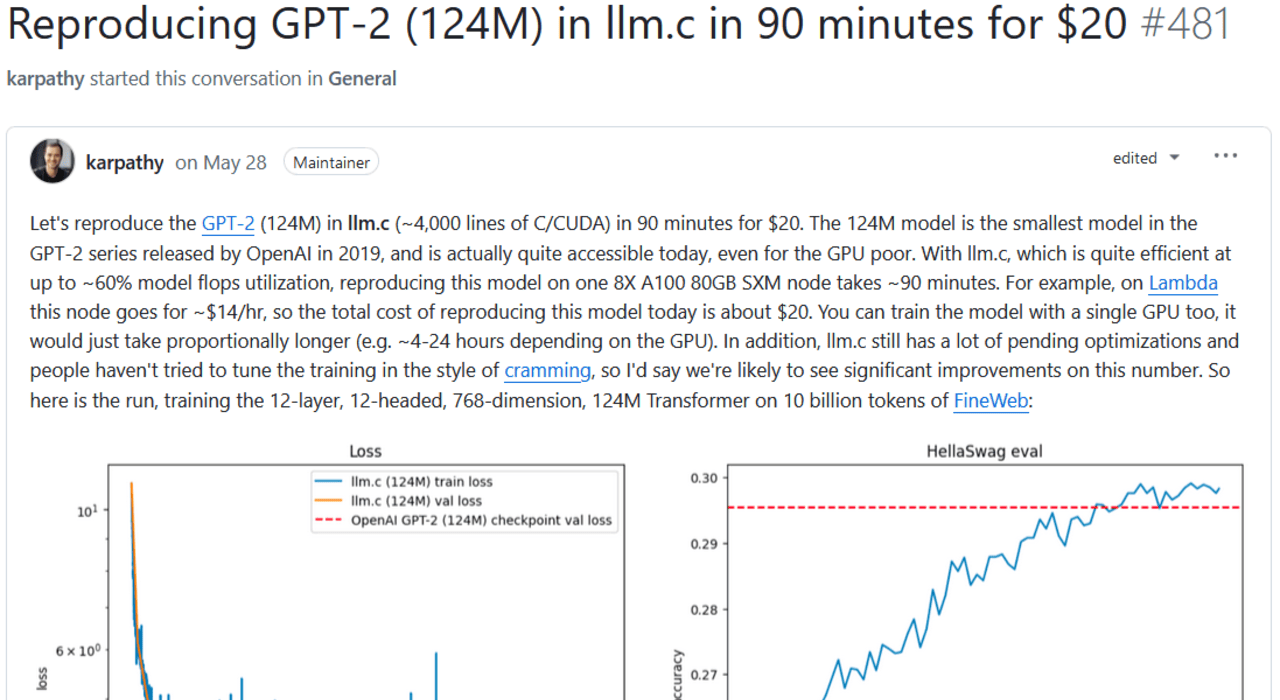
Introduction
If you’re curious about the inner workings of large language models (LLMs) but feel intimidated by the complexity of modern AI frameworks, you’re in for a treat. Andrej Karpathy, a leader in the AI space, has released “llm.c”, a pure C implementation of GPT-2 in less than 1,000 lines of code. This stripped-down version eliminates the need for bulky frameworks like PyTorch and simplifies the AI model’s functionality. It’s designed to run directly on a CPU, making it accessible for developers and researchers who don’t have access to high-powered GPUs.
Let’s dive into why “llm.c” is such a breakthrough.
The Power of Language Models
Large language models like GPT-2 and GPT-3 have revolutionized natural language processing (NLP). These models generate human-like text, enabling advancements in everything from chatbots to content summarization. However, the resource-heavy nature of training these models has often placed them out of reach for most developers. Enter “llm.c”—a minimalist approach that makes it easier for everyone to understand, modify, and work with LLMs, without the need for expensive computational infrastructure.
How “llm.c” Works: Breaking Down the Model
In “llm.c”, Karpathy reduces the complexity of GPT-2 to its essential parts, using pure C to provide a transparent look into how LLMs work. Here’s what you can expect to learn:
- Tokenization: Breaking down raw text into tokens that the model can process.
- Embedding Layers: Turning those tokens into vectors that the model can understand.
- Transformer Blocks: Using self-attention mechanisms to capture the relationships between words in a text.
- Output Layers: Generating predictions or responses based on processed inputs.
By offering this compact implementation in C, Karpathy allows developers to dig into the code, examine each component, and get hands-on experience with how these complex models operate—without relying on high-level libraries that can obscure the inner workings.
Quick Start and Installation
Getting started with “llm.c” is straightforward, and you don’t need any heavy setups. To begin, Karpathy provides a detailed guide in the GitHub Discussions section, walking you through how to reproduce the GPT-2 (124M) model.
For those using a single GPU or looking to train on CPUs, “llm.c” offers a quick start guide specifically for fp32 (floating-point 32-bit precision). The build process is as simple as running the make command. There’s even a debugging tip—replace the -O3 flag with -g to step through the code in your favorite IDE, such as VSCode, to really understand what’s going on under the hood.
Educational Benefits: A Hands-on Learning Tool
What truly sets “llm.c” apart is its educational value. By eliminating the need for high-level frameworks, this project allows developers to:
- Grasp the Fundamentals: With just a few hundred lines of code, you can clearly see each operation and learn the key components of a GPT-2 model.
- Access to AI Without the Hefty Resources: Unlike traditional models, you don’t need expensive GPU clusters to explore AI. “llm.c” runs efficiently on most CPUs.
- Experiment and Innovate: The code is simple enough that you can customize it, trying out different architectures or optimizations to deepen your understanding of AI.
For developers new to AI, this is a goldmine—a real opportunity to understand how the magic happens without being overwhelmed by abstraction layers.
Challenges and Areas for Improvement
No project is without its challenges, and “llm.c” is no different. While it’s an excellent tool for learning and experimentation, training large models on a CPU is still time-consuming and resource-intensive. Here are a few challenges you may face:
- Computational Efficiency: CPUs, even powerful ones, are far slower than GPUs for tasks like model training.
- Precision Limitations: The model operates in 32-bit precision, which isn’t ideal for all applications.
- Time and Resource Demands: Training large language models will still require significant time, especially on CPUs.
That said, Karpathy is already working on addressing these issues. Upcoming improvements include:
- Direct CUDA Support: GPU acceleration will drastically improve training speeds.
- SIMD Instructions: Expect optimized performance through AVX2 and NEON operations, improving efficiency on x86 and ARM architectures.
- Support for Modern Architectures: Karpathy plans to adapt “llm.c” to support newer models like Llama2, offering even greater efficiency and capability.
Community and Contribution
One of the most exciting aspects of “llm.c” is the vibrant community growing around it. Developers can contribute by opening issues or pull requests on GitHub, and Karpathy has even created a Discord channel for faster collaboration. Whether you want to ask questions, contribute to the project, or simply discuss AI, you can join the conversation.
Beyond the original C/CUDA implementation, there are numerous ports of the project in other languages, such as Rust, Java, Swift, and even OpenCL. These ports demonstrate the versatility of “llm.c” and provide more opportunities for developers in different ecosystems to engage with the project.
Impact on the AI Community
“llm.c” is more than just a project; it’s a movement toward open, accessible AI. By breaking down the barriers to understanding and training language models, Karpathy is fostering a more inclusive AI community where developers of all skill levels can contribute. Here’s how “llm.c” is impacting the AI world:
- Lowering Barriers: Developers without access to high-end GPUs can still learn and experiment with cutting-edge AI technologies.
- Encouraging Innovation: With its simple, transparent code, “llm.c” invites others to modify, improve, and expand on the work.
- Promoting Education: This project is a fantastic learning tool for anyone interested in AI, making it easier for educators to teach the principles of LLMs.
Conclusion
Andrej Karpathy’s “llm.c” is a landmark project in the AI space, offering a pure C implementation of GPT-2 in less than 1,000 lines of code. By making LLMs more accessible and easier to understand, “llm.c” opens the door to a new generation of developers eager to explore the power of AI. With ongoing improvements like GPU support and CPU optimizations on the horizon, “llm.c” will likely continue to grow in both capability and influence.
Whether you’re an AI veteran or just starting your journey, “llm.c” is a project you don’t want to miss. Dive into the GitHub repository, join the community on Discord, and get your hands dirty with the future of AI.